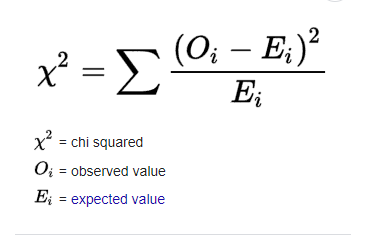One Sample T-test in R

One sample t-test is a fundamental statistical tool used to determine whether the mean of a single sample differs significantly from a known or hypothesized population mean. It is especially useful when the population standard deviation is unknown and the sample size is relatively small. This blog post provides a comprehensive overview of the one … Read more