The one-way analysis of variance (ANOVA) is used to determine whether there are any statistically significant differences between the means of three or more independent (unrelated) groups. This guide will provide a brief introduction to the one-way ANOVA, including the assumptions of the test and when you should use this test. One-way ANOVA contains the following steps:
- Clear R environment
- Importing data
- One way ANOVA
- Mean separation test
- TukeyHSD test
- LSD test
- Scheffe test
- Visualizing results
In this tutorial, you will learn how to carry out a one-way analysis of variance. One way analysis of variance compares the means of the samples or groups in order to make inferences about the population means. The One-way ANOVA is also called a single factor analysis of variance because there is only one independent variable or factor.
So let’s get started!
Clear R environment
As a first step, I always recommend clearing data objects and values in the global environment with rm() function. Set TRUE value for the argument all to remove objects and values if you have created earlier. Shut down all the graphic windows by using graphics.off() function. Putting the value “cls” in shell() function will clear the console environment.
rm(list = ls(all = TRUE))
graphics.off()
shell("cls")Importing data
To import the data set I have placed the excel data file in the project working directory. Load the library readxl to access its functions. Create an object data and assign to it a function which I am calling as read_excel(). In argument path after equal the sign within quotations just press tab button to access the files present in the working directory. Now we need to choose the respective excel data file. In the next argument col_names type TRUE to indicate that the first row of the data file contains variable names or headings.
In the next line we can use the head() function to print the first six rows of the data frame. Here I am converting the first 3 variables as factor variables by using as.factor() function. Use attach() function for data object to mask the components of the variables in the data frame.
library(readxl)
data = read_excel(
path = 'one-way-data.xlsx',
col_names = TRUE
)
head(data)
data$Treatment = as.factor(data$Treatment)
attach(data)# # A tibble: 6 x 2
# Treatment Yield
# <chr> <dbl>
# 1 Ctrl 29.8
# 2 Ctrl 23
# 3 Ctrl 24.3
# 4 NP 16.2
# 5 NP 11.9
# 6 NP 14.4There are two variables in the imported data. One is the independent variable labelled as Treatment. The second is the dependent variable labelled as Yield. The treatment factor is comprised of four different levels. These levels are control, nutrient priming, hydro priming and Osmo priming.
One way ANOVA
We wish to investigate if there are statistically significant variations in sweet potato yield between the groups of treatment variables. We must first do an analysis of variance. The aov() function will return the analysis of variance table where in parenthesis we can specify or response variable separated by treatment or factor variable. You can get anova summary by using summary() function for anova object. This will reveal whether or not the treatment’s effect is significant.
anova <- aov(Yield ~ Treatment)
summary(anova)# Df Sum Sq Mean Sq F value Pr(>F)
# Treatment 3 1170.2 390.1 17.34 0.000733 ***
# Residuals 8 179.9 22.5
# ---
# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1We can see the attributes of ANOVA by using the attributes function for ANOVA object.
attributes(anova)# $names
# [1] "coefficients" "residuals" "effects" "rank"
# [5] "fitted.values" "assign" "qr" "df.residual"
# [9] "contrasts" "xlevels" "call" "terms"
# [13] "model"
#
# $class
# [1] "aov" "lm"You can also get information for the means by typing model.tables() function for ANOVA.
model.tables(anova, "means")# Tables of means
# Grand mean
#
# 28.925
#
# Treatment
# Treatment
# Ctrl HP NP OP
# 25.70 37.63 14.17 38.20Mean separation test for one-way ANOVA
TukeyHSD test
Tukey HSD ANOVA may also be used to examine crucial values and probability at a 95% confidence interval using the TukeyHSD() function.
TukeyHSD(x = anova,
which = "Treatment",
conf.level = 0.95)# Tukey multiple comparisons of means
# 95% family-wise confidence level
#
# Fit: aov(formula = Yield ~ Treatment)
#
# $Treatment
# diff lwr upr p adj
# HP-Ctrl 11.9333333 -0.4663365 24.3330031 0.0592490
# NP-Ctrl -11.5333333 -23.9330031 0.8663365 0.0685547
# OP-Ctrl 12.5000000 0.1003302 24.8996698 0.0482107
# NP-HP -23.4666667 -35.8663365 -11.0669969 0.0013612
# OP-HP 0.5666667 -11.8330031 12.9663365 0.9987858
# OP-NP 24.0333333 11.6336635 36.4330031 0.0011621LSD test
LSD test can also be performed by using LSD.test() function. You need to load library agricolae to use this function. The argument y specify the model as aov() or lm(). The trt argument specify a character value representing the treatment variable.
library(agricolae)
LSD = LSD.test(y = anova,
trt = "Treatment",
DFerror = anova$df.residual,
MSerror = deviance(anova)/anova$df.residual,
alpha = 0.05,
group = TRUE,
console = TRUE)#
# Study: anova ~ "Treatment"
#
# LSD t Test for Yield
#
# Mean Square Error: 22.48917
#
# Treatment, means and individual ( 95 %) CI
#
# Yield std r LCL UCL Min Max
# Ctrl 25.70000 3.609709 3 19.386268 32.01373 23.0 29.8
# HP 37.63333 7.333030 3 31.319601 43.94707 29.3 43.1
# NP 14.16667 2.159475 3 7.852935 20.48040 11.9 16.2
# OP 38.20000 4.300000 3 31.886268 44.51373 33.4 41.7
#
# Alpha: 0.05 ; DF Error: 8
# Critical Value of t: 2.306004
#
# least Significant Difference: 8.928965
#
# Treatments with the same letter are not significantly different.
#
# Yield groups
# OP 38.20000 a
# HP 37.63333 a
# Ctrl 25.70000 b
# NP 14.16667 cScheffe test
Similarly, one can also use scheffe test with similar arguments as used in LSD test in above code. The only difference is that you can also specify the F value in Fc argument.
scheffe.test(y = anova,
trt = "Treatment",
DFerror = anova$df.residual,
MSerror = deviance(anova)/anova$df.residual,
Fc = summary(anova)[[1]][1,4],
alpha = 0.05,
group = TRUE,
console = TRUE)#
# Study: anova ~ "Treatment"
#
# Scheffe Test for Yield
#
# Mean Square Error : 22.48917
#
# Treatment, means
#
# Yield std r Min Max
# Ctrl 25.70000 3.609709 3 23.0 29.8
# HP 37.63333 7.333030 3 29.3 43.1
# NP 14.16667 2.159475 3 11.9 16.2
# OP 38.20000 4.300000 3 33.4 41.7
#
# Alpha: 0.05 ; DF Error: 8
# Critical Value of F: 4.066181
#
# Minimum Significant Difference: 13.52368
#
# Means with the same letter are not significantly different.
#
# Yield groups
# OP 38.20000 a
# HP 37.63333 a
# Ctrl 25.70000 ab
# NP 14.16667 bVisualizing results of One-way ANOVA
The results can be visualized using bar.err() function. It plots bars of the averages of treatments and standard error or standard deviance. It uses the objects generated by a procedure of comparisons like LSD, HSD, Kruskal and Waller-Duncan.
The argument x specify the object means of the comparisons as mentioned above. In variation you can specify the values as SE, range and IQR.
bar.err(x = LSD$means,
variation = "SE",
ylim = c(0,45),
angle = 125,
density = 6)
title(main = "Standard deviation",
cex.main = 1,
xlab = "Seed priming",ylab = "Yield")
bar.err(x = LSD$means,
variation = "range",
ylim = c(0,45),
bar = FALSE,
col = "green")
title(main = "Range",
cex.main = 1,
xlab = "Seed priming",ylab = "Yield")

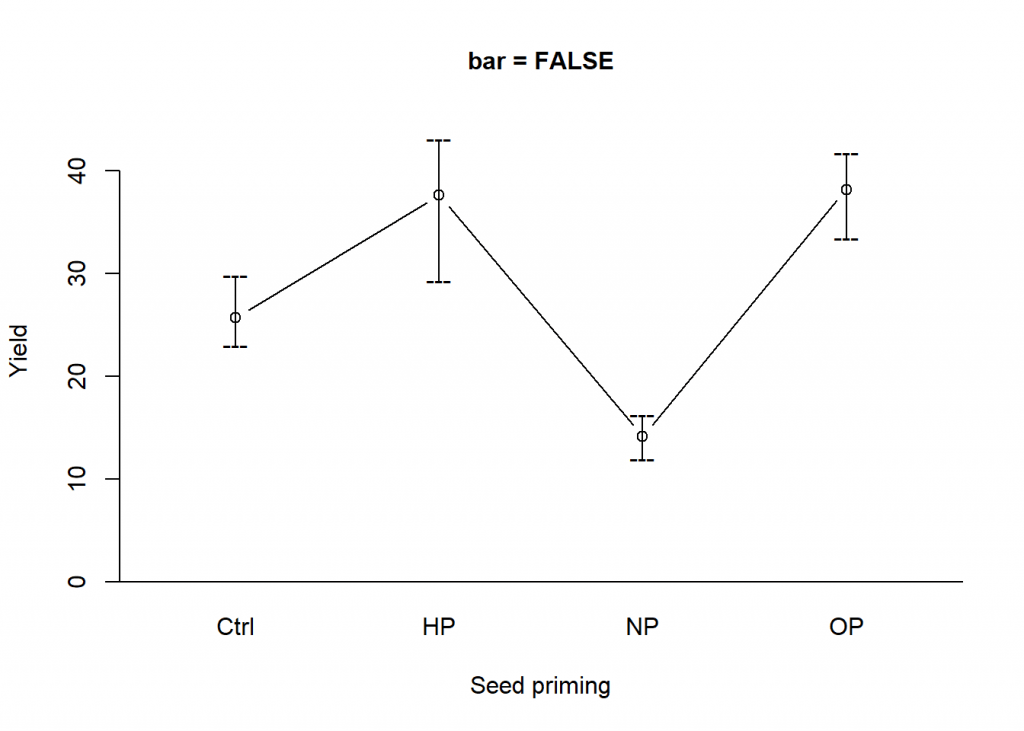
From the above plots you can remove the bars to only show the error bars by setting the logical value of bar argument to FALSE.
bar.err(x = LSD$means,
variation = "range",
ylim = c(0,45),
bar = FALSE,
col = 0)
abline(h = 0)
title(main = "bar = FALSE",
cex.main = 1,
xlab = "Seed priming",ylab = "Yield")