We’ll be learning about data cleaning and editing in this session. Data cleaning is a process that checks to see if your variables’ values are valid. We do data coding in order to make data (participants’ responses) more manageable, in a numeric format that statistical software like Stata, SPSS, or Excel can understand, allowing you to analyze them, as you recall from last week’s lesson. So, how do you double-check that your variable values were input correctly? To some extent, although not totally, we can check for accuracy.
Data cleaning and editing
For example, in your Happiness Survey data (code file), if we were to investigate if the values of variable “political affiliation” were entered correctly, we use the command: “summary” or “sum” in short, of that variable that was coded as “Pol”. The values of this variable range from 1-3 in which 1 indicates Democrat, 2 Republican, and 3 None. When you use the command “sum” it will give you Observation (your number of your respondents), Mean (or the average), Std. Dev. (standard deviation), Min (minimum) and Max (maximum). So here how it looks like in Stata:

Note that Pol has three possible values, but it only displays Min 1 and Max 4 here. So there’s a problem with the data we submitted; notably, the value 4 should not be included. So, based on the ID connected with this number, the next step is to look for the number 4. Now we’ll use the command “tabulation” (abbreviated “tab”). So, in the command prompt, type “tab Pol.” Here’s how it appears:
tab Pol 
Editing
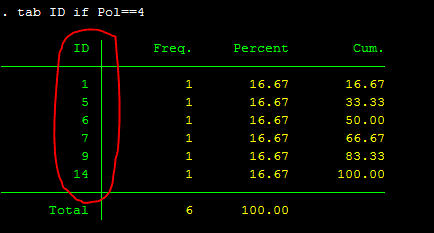
Now we can see that there are 6 respondents with a value of 4. And you immediately suspect Gail made a mistake when entering the data for these six responders. As a result, we must verify the identities of these six individuals. We can return to your paper questionnaire once we get the IDs. This is why, before you add any data, you must always ID your questionnaire so that we can always refer back to the original source. To find out who are these 6 respondents, we use the command: “tab”. So now we “tab ID” with enforced condition only for the variable Pol that has the value of 4. The conditional command is “if”. So here how it looks like with the conditional command: “tab ID if Pol==4”. Note that the equal sign is double, and variables in STATA are case sensitive. Here is how the output looks like:
tab ID if Pol==4You now have a better idea of which questionnaire to look into. If you have the questionnaires in front of you, you can search for them using the following IDs: 1, 5, 6, 7, 9, 14. The next step is to use the command “edit” to correct it. Other conditional commands, such as “|,” will also be utilized. This “|” instructs Stata to select a specific number of IDs to get. Only if Pol equal to 4, we want to get the following IDs: 1, 5, 6, 7, 9, and 14. “edit Pol if (ID==1 | ID==5 | ID==6 | ID==7 | ID==9 | ID==14)” should be typed into your command box. Note that we use parenthesis right after “if” so Stata knows that you want to request 1 and 5 and 6 and so on. You can also do it one at a time. For example, “edit Pol if ID==1”, “edit Pol if ID==5” and so on. Either way that you are comfortable with. So here is how it looks like after you type, “edit Pol if (ID==1 | ID==5 | ID==6 | ID==7 | ID==9 | ID==14)” in your command box:
edit Pol if (ID==1 | ID==5 | ID==6 | ID==7 | ID==9 | ID==14)Data editor
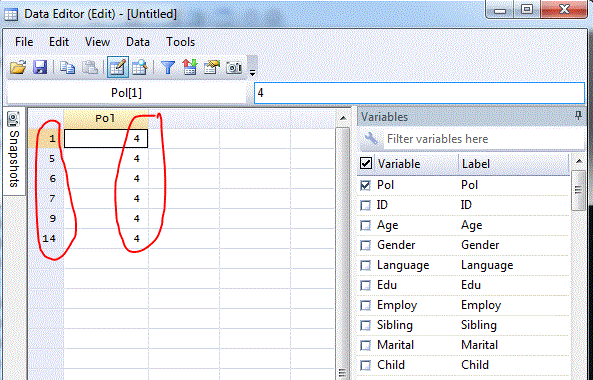
Stata now returns all of the IDs with the value 4 for Pol that you requested. Now you can change the value of the Pol variable in the above Window to the value you found in your paper questionnaire. So, this is the easy way of cleaning and editing data using Stata.